İçindekiler
1. İşletim Sistemi
2. Kabuk
3. Prosesler
4. İplikler
5. İplikler Arası Eş Zamanlama
6. Prosesler Arası İletişim
7. İş Sıralama
8. Prosesler Arası Eş zamanlama
9. Bellek Yönetimi
10. Dosya Sistemi
11. Soket Haberleşme

#include <iostream> #include <thread> #include <future> #include <algorithm> using namespace std; const int SIZE=80000000; int numbers[SIZE]; template <typename iter> void init_problem(iter beg,iter end){ int i=1; for (iter p=beg;p!=end;p++,++i) *p= i; } template <typename iter> int parallel_sum(iter begin, iter end){ long len= distance(begin,end); if (len <= 10000000){ return accumulate(begin,end,int()); } iter mid= begin + len /2; auto handle_left= async(launch::async,parallel_sum<iter>,begin,mid); auto handle_right= async(launch::async,parallel_sum<iter>,mid,end); return handle_left.get()+ handle_right.get(); } int main(){ init_problem(numbers,numbers+SIZE); int sum= parallel_sum(numbers,numbers+SIZE); cout << "Sum (parallel): " << sum << endl ; }
g++ -lpthread -O3 -std=c++11 -o parsum parsum.cpp
public class ParallelSum { private static final int SIZE = 80_000_000; private static int numbers[] = new int[SIZE]; private static void init_problem(int[] array) { for (int i = 0, j = 1; i < array.length; ++i, ++j) { array[i] = j; } } public static void solve() { int sum= Arrays.stream(numbers).parallel().sum(); System.err.println("Sum (parallel): " + sum ); } public static void main(String[] args) { init_problem(numbers); for (int i=0;i<100;++i) solve(); } }
| C++11 | Java 8 |
| 0.018948 | 0.155995 |
| 0.01986 | 0.01995 |
| 0.022167 | 0.019785 |
| 0.020191 | 0.018711 |
| 0.020895 | 0.019071 |
| 0.020394 | 0.018406 |
| 0.021172 | 0.019326 |
| 0.019818 | 0.019334 |
| 0.020595 | 0.019033 |
| 0.021555 | 0.019154 |


public class Programmer implements Serializable { private int id; private String name; private String surname; private int age; private ProgrammingLanguage programmingLanguage; . . . }
public class ProgrammingLanguage implements Serializable { private String name; private int level; . . . }
private static long serialSolve(List<Programmer> list) { long start = System.nanoTime(); Programmer oldest = null; for (Programmer programmer : list) { if (programmer.getAge() > 40 && programmer.getProgrammingLanguage().getName().equalsIgnoreCase("java")) { if (oldest == null) { oldest = programmer; } else if (programmer.getProgrammingLanguage().getLevel() > oldest.getProgrammingLanguage().getLevel()) { oldest = programmer; } } } System.err.println("Oldest [Serial]: " + oldest); long stop = System.nanoTime(); return (stop - start); }
private static long parallelSolveCallableThread(List<Programmer> list) throws InterruptedException { long start = System.nanoTime(); Programmer oldest = null; int numberOfSegments = DATA_SIZE / SERIAL_THRESHOLD; ExecutorService es = Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors()); List<Callable<Programmer>> callables = new ArrayList<>(numberOfSegments); for (int i = 0, j = 0; i < numberOfSegments; ++i, j += SERIAL_THRESHOLD) { callables.add(new ProcessingThread(j, SERIAL_THRESHOLD, list)); } List<Future<Programmer>> partialSolutions = es.invokeAll(callables); try { oldest = partialSolutions.get(0).get(); for (int i = 1; i < partialSolutions.size(); ++i) { Programmer programmer = partialSolutions.get(i).get(); if (programmer.getProgrammingLanguage().getLevel() > oldest.getProgrammingLanguage().getLevel()) { oldest = programmer; } } } catch (InterruptedException | ExecutionException ex) { Logger.getLogger(PerformanceTest.class.getName()).log(Level.SEVERE, null, ex); } System.err.println("Oldest [Callable Thread]: " + oldest); long stop = System.nanoTime(); es.shutdown(); return (stop - start); }
public class ProcessingThread implements Callable<Programmer> { private final int start; private final int length; private final List<Programmer> list; public ProcessingThread(int start, int length, List<Programmer> list) { this.start = start; this.length = length; this.list = list; } @Override public Programmer call() throws Exception { Programmer oldest = list.get(start); Programmer programmer; for (int i = start + 1, j = 1; j < length; ++j, ++i) { programmer = list.get(i); if (programmer.getAge() > 40 && programmer.getProgrammingLanguage().getName().equalsIgnoreCase("java")) { if (programmer.getProgrammingLanguage().getLevel() > oldest.getProgrammingLanguage().getLevel()) { oldest = programmer; } } } return oldest; } }
private static long parallelSolveForkJoin(List<Programmer> list) { long start = System.nanoTime(); ForkJoinPool pool = new ForkJoinPool(); ForkListProcessing flp = new ForkListProcessing(0, list.size(), list); Programmer oldest = pool.invoke(flp); System.err.println("Oldest [FJ]: " + oldest); long stop = System.nanoTime(); return (stop - start); }
public class ForkListProcessing extends RecursiveTask<Programmer> { private final int start; private final int length; private final List<Programmer> list; private static final int SERIAL_THRESHOLD = 5_000_000; public ForkListProcessing(int start, int length, List<Programmer> list) { this.start = start; this.length = length; this.list = list; } @Override public Programmer compute() { if (length <= SERIAL_THRESHOLD) { return serialSolver(); } else { int startLeft = start; int lengthLeft = length / 2; int startRight = start + lengthLeft; int lengthRight = length - lengthLeft; RecursiveTask<Programmer> left = new ForkListProcessing(startLeft, lengthLeft, list); RecursiveTask<Programmer> right = new ForkListProcessing(startRight, lengthRight, list); left.fork(); right.fork(); Programmer leftSolution = left.join(); Programmer rightSolution = right.join(); if (leftSolution.getProgrammingLanguage().getLevel() >= rightSolution.getProgrammingLanguage().getLevel()) { return leftSolution; } else { return rightSolution; } } } private Programmer serialSolver() { Programmer oldest = list.get(start); Programmer programmer; for (int i = start + 1, j = 1; j < length; ++j, ++i) { programmer = list.get(i); if (programmer.getAge() > 40 && programmer.getProgrammingLanguage().getName().equalsIgnoreCase("java")) { if (programmer.getProgrammingLanguage().getLevel() > oldest.getProgrammingLanguage().getLevel()) { oldest = programmer; } } } return oldest; } }
private static long parallelSolveMapReduce(List<Programmer> list) { long start = System.nanoTime(); Programmer oldest = list.parallelStream() .filter((Programmer prg) -> prg.getAge() > 40 && prg.getProgrammingLanguage().getName().equalsIgnoreCase("java")) .reduce((left, right) -> left.getProgrammingLanguage().getLevel() >= right.getProgrammingLanguage().getLevel() ? left : right).get(); System.err.println("Oldest [MapReduce]: " + oldest); long stop = System.nanoTime(); return (stop - start); }
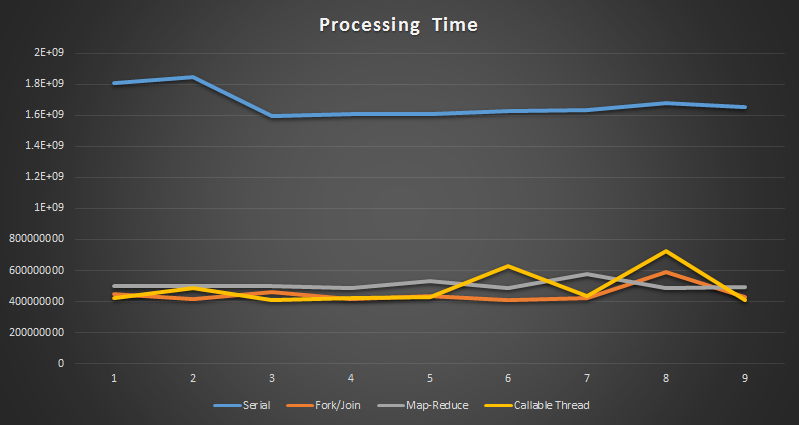
| Serial | Fork/Join | Map-Reduce | Callable Thread |
| 2668505068 | 287335266 | 2944504598 | 371450954 |
| 1520665434 | 256402330 | 220530644 | 297969676 |
| 1466104840 | 248664714 | 216625912 | 344167024 |
| 1464082558 | 253262636 | 218372802 | 298162542 |
| 1516772250 | 255020642 | 239981168 | 302813920 |
| 1524937500 | 248614678 | 214424022 | 298976328 |
| 1466208756 | 248644184 | 213896322 | 371450954 |
| 1465564738 | 250441532 | 213332274 | 299036198 |
| 1478366830 | 384069164 | 211912956 | 299329982 |
| 1459489336 | 248061746 | 211580254 | 295550550 |

| Serial | Fork/Join | Map-Reduce | Callable Thread |
| 19741743117 | 580408617 | 4701616707 | 626018473 |
| 1806017710 | 448612143 | 496646177 | 424259928 |
| 1848274359 | 417033783 | 502213371 | 484369695 |
| 1597769920 | 462913357 | 499692308 | 408970979 |
| 1610160940 | 416298935 | 486345985 | 423605953 |
| 1606404182 | 435899678 | 534527811 | 426688621 |
| 1625213014 | 408824009 | 486342701 | 626018473 |
| 1632420684 | 422062362 | 576433047 | 435159082 |
| 1680902197 | 592661288 | 489187262 | 724467204 |
| 1653464440 | 430231904 | 493916565 | 406734823 |

1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | public class TestConstantPool { public static void main(String[] args) { String s1= "Hello"; // CP String s2= "Hello"; // CP // String is immutable String s3= new String("Hello"); // Heap (Eden) String s4= new String("Hello"); // Heap (Eden) if (s1==s2){ System.out.println("s1 is equal to s2"); }else{ System.out.println("s1 is NOT equal to s2"); } if (s4==s3){ System.out.println("s1 is equal to s3"); }else{ System.out.println("s1 is NOT equal to s3"); } s3= s3.intern(); if (s1==s3){ System.out.println("s1 is equal to s3"); }else{ System.out.println("s1 is NOT equal to s3"); } } } |
public class TestInteger { public static void main(String[] args) { Integer a= 108; // CP Integer b= 108; // CP Integer m= 549; // Heap (Eden) Integer n= 549; // Heap (Eden) if (a==b){ System.out.println("a is equal to b"); } else { System.out.println("a is NoT equal to b"); } if (m==n)){ System.out.println("m is equal to n"); } else { System.out.println("m is NoT equal to n"); } } }
public class LotsOfStrings { private static final LinkedList<String> LOTS_OF_STRINGS = new LinkedList<>(); public static void main(String[] args) throws Exception { int iteration = 0; while (true) { for (int i = 0; i < 100; i++) { for (int j = 0; j < 1000; j++) { LOTS_OF_STRINGS.add(new String("String " + j)); } } iteration++; System.out.println("Survived Iteration: " + iteration); Thread.sleep(100); } } }
Survived Iteration: 1 Survived Iteration: 2 Survived Iteration: 3 Survived Iteration: 4 Survived Iteration: 5 Survived Iteration: 6 Survived Iteration: 7 Survived Iteration: 8 Survived Iteration: 9 Survived Iteration: 10 Survived Iteration: 11 Survived Iteration: 12 Survived Iteration: 13 Exception in thread "main" java.lang.OutOfMemoryError: GC overhead limit exceeded at com.example.console.LotsOfStrings.main(LotsOfStrings.java:18)
Survived Iteration: 1 Survived Iteration: 2 Survived Iteration: 3 Survived Iteration: 4 Survived Iteration: 5 Survived Iteration: 6 Survived Iteration: 7 Survived Iteration: 8 Survived Iteration: 9 Survived Iteration: 10 Survived Iteration: 11 Survived Iteration: 12 Survived Iteration: 13 Survived Iteration: 14 Survived Iteration: 15 Survived Iteration: 16 Survived Iteration: 17 Survived Iteration: 18 Survived Iteration: 19 Survived Iteration: 20 Survived Iteration: 21 Survived Iteration: 22 Survived Iteration: 23 Survived Iteration: 24 Survived Iteration: 25 Exception: java.lang.OutOfMemoryError thrown from the UncaughtExceptionHandler in thread "main" Java Result: 1
Survived Iteration: 1 Survived Iteration: 2 Survived Iteration: 3 Survived Iteration: 4 Survived Iteration: 5 Survived Iteration: 6 Survived Iteration: 7 Survived Iteration: 8 Survived Iteration: 9 Survived Iteration: 10 Survived Iteration: 11 Survived Iteration: 12 Survived Iteration: 13 Survived Iteration: 14 Survived Iteration: 15 Survived Iteration: 16 Survived Iteration: 17 Survived Iteration: 18 Survived Iteration: 19 Exception: java.lang.OutOfMemoryError thrown from the UncaughtExceptionHandler in thread "main" Java Result: 1
Survived Iteration: 1 [GC concurrent-string-deduplication, 2131.9K->39.3K(2092.6K), avg 98.2%, 0.0121525 secs] [Last Exec: 0.0121525 secs, Idle: 0.0000008 secs, Blocked: 0/0.0000000 secs] [Inspected: 54680] [Skipped: 0( 0.0%)] [Hashed: 54680(100.0%)] [Known: 0( 0.0%)] [New: 54680(100.0%) 2131.9K] [Deduplicated: 53678( 98.2%) 2092.6K( 98.2%)] [Young: 0( 0.0%) 0.0B( 0.0%)] [Old: 53678(100.0%) 2092.6K(100.0%)] [Total Exec: 1/0.0121525 secs, Idle: 1/0.0000008 secs, Blocked: 0/0.0000000 secs] [Inspected: 54680] [Skipped: 0( 0.0%)] [Hashed: 54680(100.0%)] [Known: 0( 0.0%)] [New: 54680(100.0%) 2131.9K] [Deduplicated: 53678( 98.2%) 2092.6K( 98.2%)] [Young: 0( 0.0%) 0.0B( 0.0%)] [Old: 53678(100.0%) 2092.6K(100.0%)] [Table] [Memory Usage: 49.5K] [Size: 1024, Min: 1024, Max: 16777216] [Entries: 1770, Load: 172.9%, Cached: 0, Added: 1770, Removed: 0] [Resize Count: 0, Shrink Threshold: 682(66.7%), Grow Threshold: 2048(200.0%)] [Rehash Count: 0, Rehash Threshold: 120, Hash Seed: 0x0] [Age Threshold: 3] [Queue] [Dropped: 0]
[GC concurrent-string-deduplication, 2131.9K->39.3K(2092.6K), avg 98.2%, 0.0121525 secs]
Bu satırdan, String deduplication için ne kadar süre harcandığı ve ortalama ne kadar yineleme yakalandığını okumak mümkündür. Karar sizin.